

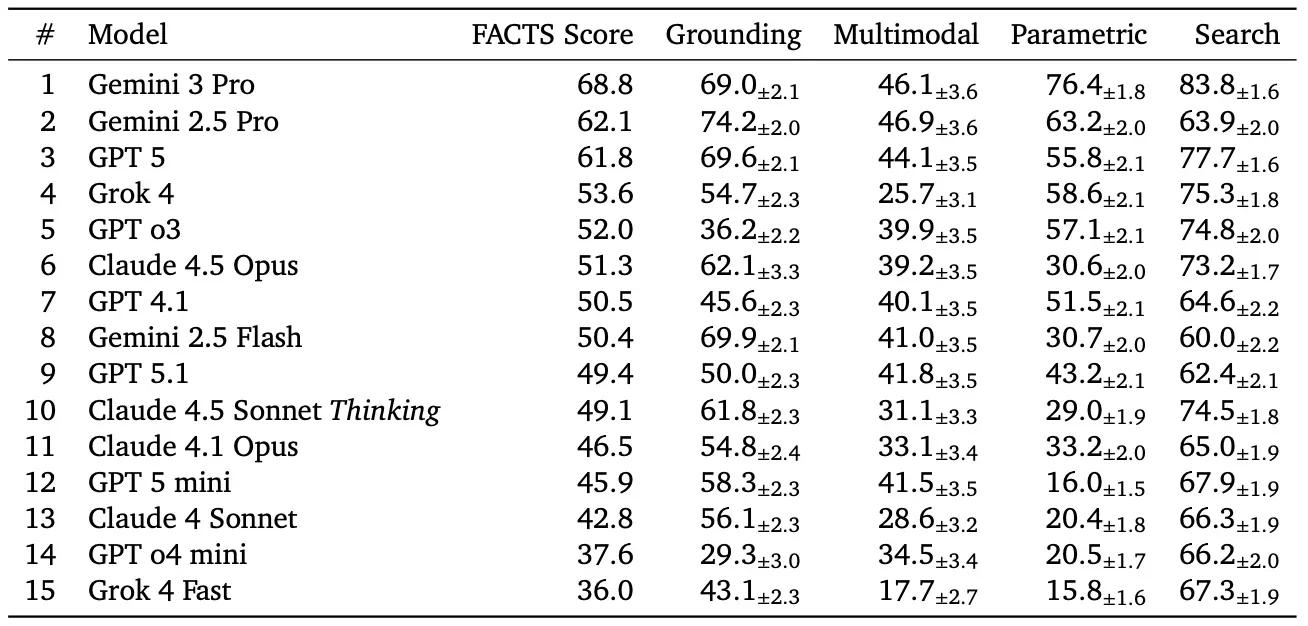
Наивысший результат в 69% общей точности показала модель Gemini 3 Pro, а другие распространённые системы, такие как ChatGPT-5, Claude 4.5 Opus и Grok 4, продемонстрировали результаты в диапазоне от 51% до 62%. Особенно низкие показатели были зафиксированы в заданиях, требующих анализа визуальных данных, где точность часто опускалась ниже 50%.
Результаты указывают на то, что в среднем каждый третий ответ, сгенерированный чат-ботом, может содержать фактические ошибки, при этом системы часто выдают информацию с высокой степенью «уверенности», что может вводить пользователей в заблуждение.

Многие существующие методы оценки ИИ сосредоточены на способности модели выполнить задачу, а не на фактической достоверности её ответов. Новое исследование подчёркивает необходимость дополнительной проверки информации, полученной от ИИ-ассистентов, особенно в профессиональных контекстах. Вопрос эффективности такой работы остаётся открытым. ведь в некоторых случаях ручная проверка ответов может занять больше времени, чем самостоятельное решение задачи.
🐻 Делаем удивлённые лица: зрителям зашёл «Пять ночей у Фредди 2» — вопреки мнению критиков
+2
Поделиться:
НовостиЖелезо и технологииАналитика и статистикаGoogleнейросети
Об авторе

3D-миры по текстовому описанию: нейросеть Marble стала доступна всем желающим

Нейросеть DeepSeek победила на нескольких математических олимпиадах

«Вайбкодинг» в действии: анонсирована игра, целиком сделанная нейросетями

Рекламная модель интернета под угрозой из-за развития нейросетей

Нейросеть Google теперь может работать с сайтами вместо человека
По материалам: vgtimes.ru
















